Alexa, When's the Next Bus: Wellington Public Transport
October 29, 2024 | 2242 words | 10 min
This blog covers the development of an Alexa Skill for real-time public transport in Wellington, built to optimize performance within Alexa’s free tier limits. It delves into the technical challenges faced, including response time constraints and architecture decisions, while also enhancing accessibility for users.
Introduction
Ever been in a rush in the morning without the time to navigate the Metlink app to find you just missed your bus or train? This exact scenario is why Isaac Young and I created an Alexa Skill to provide real-time public transport information just with your voice.
Our motivation for this project stemmed from a shared desire to make our daily commutes easier and more predictable. We also aimed to improve accessibility, particularly for people with low vision, by offering a voice-activated solution that simplifies accessing public transport information.
In this post I'll dive into what we can do with our Alexa Skill followed by a technical deep dive on our journey to finally releasing this long-awaited project.
Getting Started with the Alexa Skill
You can install our Alexa Skill to your echo by finding us under Wellington Public Transport. Below is a quick starter guide on how to try out our skill.
Start by opening the skill and saying "Alexa, open Wellington Transport"
Personalised Stop Setting
Just set your stop and you're good to go:
- "Alexa, set my bus stop to [stop id]."
- "Alexa, set my train station to [station id]."
Note: we only accept the stop/station id as an input, check either the Metlink website or Catchy to find your stop.
Live Departures Display
Want to know when the next bus or train is leaving? Just ask:
- "Alexa, when is the next bus from my stop?"
- "Alexa, when is the next train from my station?"
Wellington Transport will provide you with real-time departure information for the next available service.
Direction-specific Trains
If you're a train commuter and need to know the departure time for a specific direction, try:
- "Alexa, when is the next inbound train from my station?"
- "Alexa, when is the next outbound train from my station?"
Next Departure
Planning ahead? Find out the departure time for the bus or train after the next one:
- "Alexa, when is the bus after that?"
- "Alexa, when is the train after that?"
Wellington Transport will promptly provide the upcoming departure time.
Recall Previous Inquiries
Missed the information from a previous query? Retrieve it easily by asking:
- "Alexa, when is that bus I asked about earlier?"
- "Alexa, when is that train I asked about earlier?"
What's My Stop
Curious about which stop or station you've set as your default? Just say:
- "Alexa, what's my bus stop?"
- "Alexa, what's my train station?"
There is a lot more that we could delve into here but for brevity we'll end this section here. If you have any issues feel free to reach out to me personally on LinkedIn.
Example visual responses

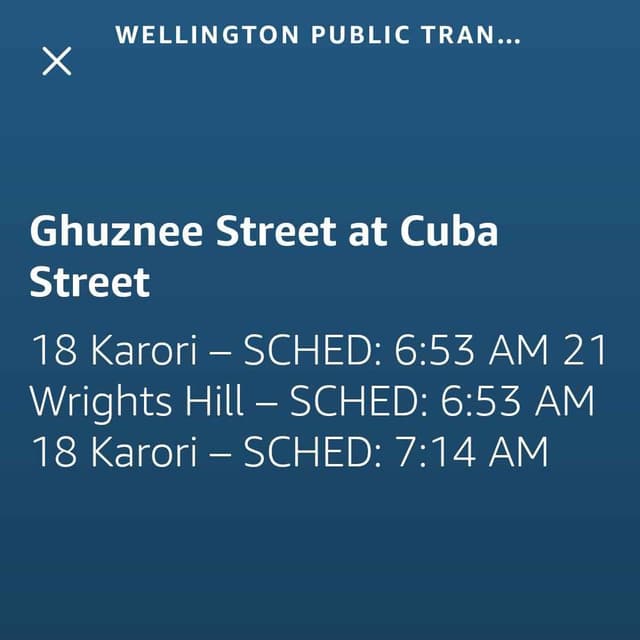

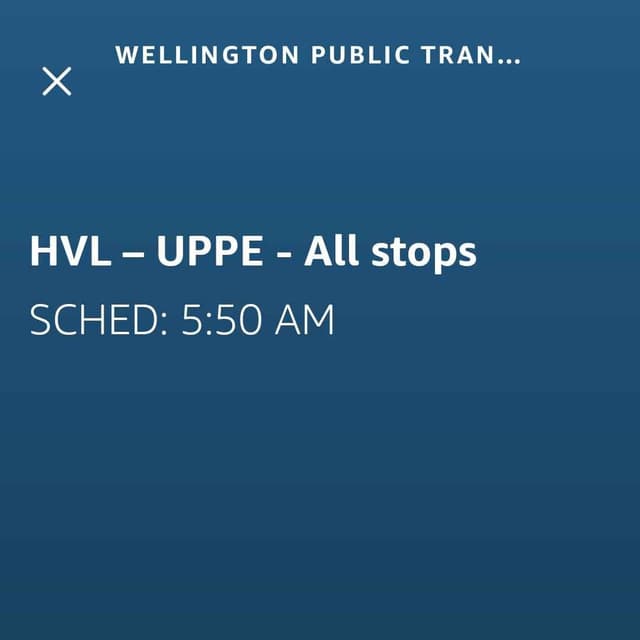
Overcoming Technical Challenges
Building this Alexa Skill wasn't just about connecting APIs. A key challenge was optimizing performance, particularly because the skill is hosted on Alexa's free tier, located in us-west-2, while the Metlink API endpoints terminate in Auckland.
The most important constraint, however, is the execution time limit for an Alexa skill to response - which is 8 seconds. This meant that we needed to be frugal with our network requests as they would take a minimum of 500ms each else we would have our conversation terminated.
Alongside these latency concerns, there was also a limit on the number of files and the total size of the artefact uploaded. This limit was 100 files and 6MB of data. This means we're going to have to do something smart if our architecture gets too big. Spoilers: We did.
Building Within Constraints: Technology Stack and Free Tier Limitations
Optimizing Language and Build Pipeline
We chose to create this in TypeScript due to its stricter type safety and familiarity. As this is not a compiled language, the number of files when we transpile to JavaScript remains the same as before. This became an issue for us, because as of this blog, we have 107 files in describing the whole architecture crossing that 100 file limit. The solution of this is relatively simple though and lends a hand from optimizing websites - minification.
During our build process we minify our transpiled JavaScript into a singular index.js file. However, if we encounter an error, similar to websites, we get a stack trace that corresponds to the minified JavaScript code, not our original TypeScript code. This, unsurprisingly, is very unhelpful for debugging. What can help us here though is ✨ sourcemaps ✨, which I don't think get enough attention, so I'm going to touch on them again later.
Reducing Latency through Network Call Optimization
As I alluded to earlier, having a hard stop at 8s on the response time of our skill's lambda made things difficult, especially given that the free tier is provisioned in us-west-2. To minimize latency, we focused on reducing the number of network calls, parallelizing tasks wherever possible, and starting creating promises as early as possible. By batching requests and caching results, we were able to deliver fast responses even under these constraints.
For example, in the Metlink API a stop may have multiple child stops. In this case we want to parallelize the request to get all the stop responses rather than doing this sequentially.
const combinedRoutesRes = await Promise.all([
this.getAllRoutes(savedStop.stop.stopId),
...savedStop.childStops.map((it) => this.getAllRoutes(it.stopId)),
]);Sometimes it is inevitable that we run into situations that are sequential in nature, such as the example below where we have dependant requests.
async getStopsOfServiceId(serviceId: string): Promise<Result<Stop[], Error>> {
const routeRes = await this.getRoute(serviceId);
if (routeRes.err) {
return routeRes;
}
if (!routeRes.val) {
return makeErr(Error("Route returned null"));
}
const stopsRes = await this.getStopsOfRoute(routeRes.val);
if (stopsRes.err) return stopsRes;
return Ok(stopsRes.val);
}However, we can still attempt to minimize the latency through caching, which is what we have done on subsequent conversation requests where we cache the API result in the session state. We could go a step further and also store our own cache of the Metlink API's Stop endpoint but our response times are good enough for now.
Enhancing Developer and User Experience
During the development of the Wellington Public Transport Alexa Skill one of our main focuses was on ensuring a smooth experience both for the users interacting with the skill and for the us (the develoeprs) to maintain and enhance it. This is one of the reasons why we've iterated on the solution so much and refined it down to what we think is all you need feature wise. During this refinement process we also had a hard think about how failure states should be communicated to the user.
Our final approach addressed both the developer maintainability and user experience by using the Result<T, E> pattern so we can fail up (combined with a really nice architecture, but that could be a whole other blog). We also made use of logging through Cloudwatch and crash (error) reporting through Raygun to provide post deployment monitoring.
Failing up: The Result Pattern and User-Friendly Error Messages
By adopting the Result pattern we knew at each method call what we can expect from this, e.g. a Ok<T> or an Err. While you could argue that this is just try catch throw with different syntax, it's not. The main difference here is that the Result pattern requires explicit error handling for both cases at every method call, making error propagation clear and thus preventing unexpected exceptions from bubbling up silently. This leads to more predictable control flow and easier debugging, as all outcomes must be addressed rather than potentially ignored.
Knowing the flow of errors and the type of errors we expect allows us to nicely handle error states that could affect the users. For example if we expect that the stop ID the user provides can be non-existent we must handle that case and then re-prompt asking for the correct stop ID.
private async handleSaveMyBusStopQuestion(
question: SaveMyBusStopQuestion,
): Promise<Result<SaveMyBusStopAnswer, Error>> {
// Destructuring isn't highlighting correctly
// Correct syntax is [persistentState, stopRes]
const persistentState, stopRes = await Promise.all([
question.persistentState,
this.edge.getStop(question.userStopId, Optional.none()),
]);
if (stopRes.err) return stopRes;
persistentState.mutate((pState) => {
pState.userStop = stopRes.val;
});
return Ok(new SaveMyBusStopAnswer(stopRes.val));
}Re-prompting is one of the most important usability features we explored and implemented. We could have sent a reply saying "this is not valid", but to enhance user experience it's nicer to be asked again so they do not have to repeat the whole invocation phrase.
Observation and Logging: Sourcemaps, Raygun, and CloudWatch Logs
The other key part to making maintainable software is observability. This includes bugs, performance bottlenecks, and other useful analytics. Through Cloudwatch Logs we measure load times of the network calls including start time and end time which can allow us to diagnose what calls overlapping/what can be overlapped. Additionally, we control flow that is of interest so we can trace back if we have an error.
Then by using Raygun and reporting any errors using makeErr we can know when our skill is in a bad state and conduct further investigation. Keen eyes may have noticed its usage in some of the snippets in this blog.
export function makeErr<T extends Error>(err: T): Err<T> {
// RaygunClient is a wrapper around the Raygun4Node provider
RaygunClient.send(err);
return Err(err);
}Included in the error reports we have the unmappedColumnNumber and unmappedLineNumber, these allow us to symbolicate to a useful stack trace despite our code being minified. We've finally circled back to sourcemaps, so I can finally go a bit more in a little bit more detail.
When we build our project we get our index.js file and a index.js.map file. This .map file is the secret ingredient in the sourcemap sauce. It stores the mappings from line/column numbers to their original source, the source code can also be embedded in the sourcemap. This means that when you symbolicate the sourcemap you can also get snippets of code from where that line is mapped to rather than something like error at line 1 column 23984.
Raygun does this for us automatically, which is such a great feature as instead of cross-referencing the files we can already see stack trace with the surrounding context already.
We used gulp.js for our build pipeline (don't ask me why), there are other alternatives we could try out such as WebPack, or better yet, Vite with useful features such as tree shaking and much faster build times. Gulp builds both our minified file and produces the .map file required for source mapping which we then upload to Raygun using the new sourcemap upload endpoints automatically.
gulp.task("bundle", function () {
return browserify({
basedir: ".",
entries: `lambda/lambda/index.ts`,
standalone: "VISTA",
debug: true, // Ensure sourcemaps are turned on
ignoreMissing: true,
bundleExternal: false,
})
.plugin(tsify, { project: "./tsconfig.gulp.json" })
.bundle()
.pipe(source("index.js"))
.pipe(buffer()) // Convert from streaming to buffered vinyl file object
.pipe(sourcemaps.init({ loadMaps: true })) // Load initial sourcemaps from input file
// Redacted secrets :)
.pipe(sourcemaps.write("./")) // Write sourcemaps file in the same directory
.pipe(gulp.dest(BUNDLE_OUT_DIR));
});Again there's a lot more to sourcemaps as they're a fascinating topic, but that could be for another blog - maybe on how we could version build to sourcemap pairs. Though for now I'll leave it there.
Conclusion
We've finally reached the end of my first blog on my new site. I really hope you enjoyed it as much as I enjoyed writing this piece and working on the project. There's been a ton of learnings over the course of this project, and likely more to come as I keep maintaining this. If there are any suggestions, be it changes to the blog, feature requests, or whatever, feel free to reach out to me on LinkedIn.
If you enjoyed this blog I do have a bunch more planned so stay tuned. They'll likely be technical deepdives on topics I've found interesting as of late, such as using ASP.NET MVC with HTMX, or some upcoming projects for WearOS apps that I'm working on.